“没有人比我更懂性能优化“
本文首发于华云数据微信公众号
随着大数据、人工智能技术的发展,越来越多的用户产生了获取GPU算力弹性计算服务的需求,GPU云主机具有突出的图形处理和高性能计算能力,适用于科学计算、视频处理、深度学习等应用场景。本文旨在分享 OpenStack 中虚拟机 GPU 性能的调优。
首先为大家简单介绍一下 NUMA 的概念。NUMA 是一种解决多 CPU 工作的技术方案,在此之前,市面上主要采用 SMP 和 MPP 两种架构。
1.SMP 技术
计算机技术发展初期,服务器都是单 CPU 结构,随着技术的发展,多 CPU 结构开始流行起来,为了满足多 CPU 共同工作的需求,SMP 技术应运而生。
如图所示,多个 CPU 通过一个总线访问存储器,因此无论在什么时候,处理器只能为内存的每个数据保持或共享唯一一个数值。
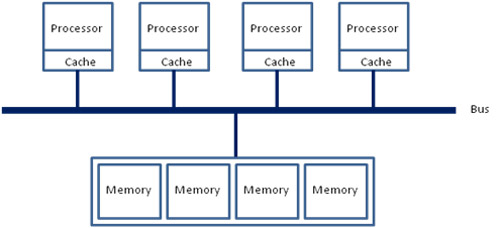
SMP 的缺点也是十分明显的,即扩展性有限,因此在存储接口达到饱和的时候,增加处理器的数量并不能获得更高的性能,因此 SMP 架构支持的 CPU 数量十分有限。
2.MPP 技术
MPP 则是一种分布式存储器模式,它能将更多的处理器纳入一个系统的存储器。一个分布式存储器具有多个节点,每个节点都有自己的存储器,单个节点相互连接形成了一个总系统。MPP 可以近似理解为一个 SMP 的横向扩展集群。
3.NUMA 技术
而 NUMA 则是每个处理器都有自己的存储器,每个处理器也可以访问其他处理器的存储器。
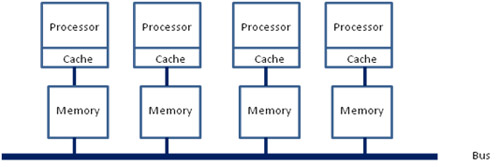
下图为多核 NUMA CPU 架构

如上文所说,每个处理器既可以访问自己的存储器,也可以访问其他处理器的存储器,而前者的速度要比后者最高快100倍。在 Linux 中系统默认采用自动 NUMA 平衡策略,所以 NUMA 调优的目的就是让处理器尽可能地访问自己的存储器,以提高计算速度。
在 OpenStack 中,可以采用 virsh numatune 命令查看和修改虚拟机的 NUMA 配置,反映在 XML 文件上的便是
那么在 GPU 云主机中,是否可以采用相同的思路进行性能调优呢?答案自然是肯定的。
在进行 GPU 性能优化前,先简单了解一下 render nodes 的概念。
render nodes 是一种用于访问具有 DRI 能力的 GPU 非特权功能的 DRM 接口,在 Linux 内核中,DRM 驱动程序通过 render-node 接口公开其用户空间 API 的非特权部分,并作为一个单独的设备文件 (/dev/dri/renderDXX) 存在。随着技术的提升,客户端不再需要运行合成器或图形服务器来使用 GPU ,通过 render node 即可实现对 GPU 资源的访问。
所以,将 GPU 和所在的 NUMA 绑定,可以防止跨片 PCIE 访问带来的性能损耗。
通过 lspci –vvvs bus_id 便可查看 GPU 所在的 NUMA 节点,即 /dev/dri/renderDXX 与 NUMA 的对应关系。以我本机为例,renderD128 对应 NUMA 0,renderD129 对应 NUMA 1,此时我们便可以使用 numactl 进行绑定。
然而在一个 OpenStack 云环境中可能会运行着成百上千的云主机,云主机创建完成后逐一进行手动绑定明显不是一个现实的方案,此时可以通过修改 /nova/virt/libvirt/driver.py中的相关逻辑进行 NUMA 绑定。当程序获取到 vcpu 被分配的 NUMA 节点后,通过设备之间的映射关系,在添加 GPU 设备阶段为其绑定对应的 render node。这样虚拟机在创建之初便拥有了卓越的性能,无需后期进行人工绑定。
结束语
本文从 NUMA 出发,为大家简单介绍了多 CPU 的常用技术架构,并以此为延伸,分享了 GPU 虚拟机的性能调优方案。目前,华云数据公有云产品线中已经包含具有超强计算能力的 GPU 型云主机,欢迎选购。
